
”HADOOP 倒排索引 MapReduce程序“ 的搜索结果
MapReduce程序 完整实验报告 和 jar包 和简单实验数据


当你把需要处理的文档上传到hdfs时,首先默认的TextInputFormat类对输入的文件进行处理,得到文件中每一行的偏移量和这一行内容的键值对做为map的输入。...这个过程中,倒排索引就起到很关键的作用。
2)第一次处理,编写OneIndexReducer类。(2)第二次处理,编写TwoIndexReducer类。(1)第一次处理,编写OneIndexMapper类。(3)第一次处理,编写...有大量的文本(文档、网页),需要建立搜索索引。...

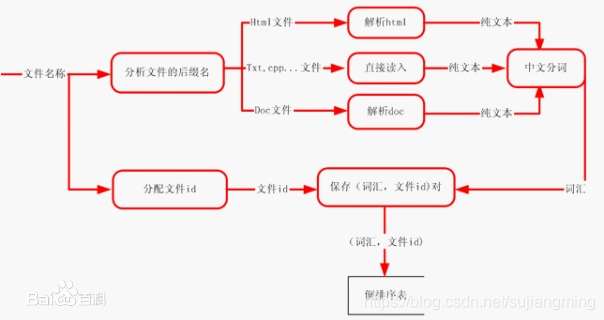
倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排索引主要用来存储某个单词(或词组)在一组文档中的存储位置的映射,提供了可以根据内容来查找文档的方式,而不是根据文档来确定内容,...
一、Hadoop 简介 下面先从一张图理解MapReduce得整个工作原理 下面对上面出现的一些名词进行介绍ResourceManager:是YARN资源控制框架的中心模块,负责集群中所有的资源的统一管理和分配。它接收来自NM...
从图 6.1-1 可以看出,单词 1 出现在{文档 1,文档 4,文档 13, ……通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的 文档或者是标识文档的 ID 号,或者是指文档所在位置的 URL,如...
维基百科数据倒排索引的Mapreduce 小心:这只是匆忙完成的家庭作业。 有些度假村不优雅先决条件下载如果您想运行 TFIDF,请设置 。 将$HADOOP_HOME/bin添加到~/.bash_profile PATH 。 或者,如果您使用的是 Windows ...
hadoop–MapReduce倒排索引 1.倒排索引介绍 倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排索引主要用来存储某个单词(或词组)在一组文档中的存储位置的映射,提供了可以根据内容来...

下面是一个基于Java实现的Hadoop倒排索引程序的示例代码: ```java import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs....

原理"倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据...
倒排索引 参考链接:https://blog.csdn.net/Xw_Classmate/article/details/50639848 “ 倒排索引”是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。 它主要是用来存储某个单词(或词组) 在一个...
(1)invertedindexmapper类继承自Mapper类,用于处理Map阶段的任务。(2)读入键值对的数据类型为,其中LongWritable用于读入key,无实际意义,Text用于读入待处理的文本句子数据。(3)输出键值对的数据类型定义为...

这篇博客文章详细介绍...接下来,我们将介绍如何在Hadoop集群上运行MapReduce任务,包括编写MapReduce程序,配置任务,以及监控任务的执行。最后,我们将分享一些优化Hadoop集群性能和MapReduce任务效率的技巧和建议。
Hadoop MapReduce倒排索引是一种用于快速查找文档中特定单词出现位置的数据结构。它通过将单词作为键,将文档ID和单词在文档中出现的位置作为值,将文档中所有单词的信息存储在一个大的分布式哈希表中。这个过程需要...

统计手机流量信息 数据去重 数据排序 平均成绩 倒排索引


倒排索引是词频统计的一个变种,其实也是做一个词频统计,不过这个词频统计需要加上文件的名称。倒排索引被广泛用来做全文检索。倒排索引最终的结果是一个单词在文件中出现的次数的集合,以下面的数据为例: file1....

推荐文章
- 配置NGINX同时运行 https 和 http_nginx 和 http无法同时启动-程序员宅基地
- 总结:linux之Service_linux service-程序员宅基地
- 揭开数据中心光模块利润之源-程序员宅基地
- Java NIO SocketChannel简述及示例_niosocketchannel-程序员宅基地
- docker内的debian9使用ntpdate同步时间时报错step-systime: Operation not permitted-程序员宅基地
- 基于功能安全的车载计算平台开发:硬件层面_mcu 不同通道 共因-程序员宅基地
- VS2022无法启动程序(系统找不到制定的文件)问题_vs2022无法启动程序找不到指定文件-程序员宅基地
- Chapter4 The Relational Model_order pairs and cartesian product-程序员宅基地
- java检查手机号是否被注册_【java】如何开发一个检测手机号注册过哪些网站的应用?...-程序员宅基地
- Android 插件化-程序员宅基地